卷积神经网络
TensorFlow官方最新的教程原文翻译。
注意:本教程针对TensorFlow高级用户并假定你对机器学习很有经验且非常专业。
概要
CIFAR-10分类是机器学习中很普遍的基础测试问题。这个测试需要对RGB 32x32像素的图片进行分类,这些分类包括了10个:
airplane, automobile, bird, cat, deer, dog, frog, horse, ship, and truck.
更多的信息请参阅CIFAR-10页面和Alex Krizhevsky的技术报告。
目标
本教程的目标是构建一个小型的卷积神经网络(CNN)来识别图片。在这个教程过程中:
- 强调使用一个权威的神经网络架构、训练和评估的组织方式。
- 提供了一个构建更大和更复杂模型的模版。
选择CIFAR-10的原因是它足够复杂可以练习很多TensorFlow的各种功能,以便扩展到更大的模型。同时这个模型又足够的小可以很快的训练,用来试验新的想法和体验新的技术。
教程的重点
CIFAR-10教程演示了在TensorFlow中设计更大和更复杂模型的几个重要结构:
- 核心数学构成包括卷积(wiki)、线性整流激活函数(wiki)、最大池化(wiki)和局部响应归一化(AlexNet论文3.3章节)
- 在训练过程中可视化神经网络的活动,包括输入的图片、损失函数值和激活函数值的分布和梯度。
- 计算学习参数的移动平均的方法并且使用这些平均值在评估阶段提升预测的性能。
- 实施随着时间系统性减少的学习率衰减。
- 输入数据使用提前队列来分离模型的磁盘延迟和高昂的图片预处理开销。
我们也提供了一个这个模型的多GPU版本,演示了:
- 配置一个模型在多GPU上并行执行
- 跨GPU共享和更新变量
希望本教程能够提供一个构建大型TensorFlow视觉任务CNN的起点。
代码的组织
本教程的代码位于models/tutorials/image/cifar10/。
| 文件 | 作用 |
|---|---|
| cifar10_input.py | 读取原始的CIFAR-10二进制格式文件 |
| cifar10.py | 构建CIFAR-10模型 |
| cifar10_train.py | 在CPU或者GPU上训练CIFAR-10模型 |
| cifar10_multi_gpu_train.py | 在多个GPU上训练CIFAR-10模型 |
| cifar10_eval.py | 评估CIFAR-10模型的预测性能 |
CIFAR-10模型
CIFAR-10神经网络的大部分代码都在cifar10.py中。完整的训练计算图包含大概765个操作。我们发现可以通过以下方式组织代码可以更好的重用代码:
- 模型输入:
inputs()和distorted_inputs()分别为评估和训练增加了读取和预处理CIFAR图片的操作。 - 模型预测:
inference()增加了预测操作,就是基于提供的图片进行分类。 - 模型训练:
loss()和train()增加了计算损失值、梯度、变量更新和产生可视化概要的操作。
模型输入
模型的输入部分构建了一个inputs()和distorted_inputs()函数用来读取CIFAR-10二进制图片文件。这些文件具有固定的文件大小,所以我们使用tf.FixedLengthRedordReader。参看读取数据部分来更深入了解Reader类是怎样工作的。
图片是按如下方式进行处理的:
为了训练我们还额外应用了一系列随机的失真,来人为的增加数据集的量:
可用失真操作列表可参看图片页面。我们也对图片使用了tf.summary.image,这样就可以在TensorBoard中看到这些图片了。这是一个确认构建输入的正确性很好的方法。

从磁盘读取图像并进行失真可以使用不重要的处理时间。为了防止这些操作放慢训练速度,我们在连续填充TensorFlow队列的16个独立线程中运行它们。
模型预测
模型预测部分是通过inference()函数构建的,增加了计算逻辑回归预测的操作。这个部分的模型是通过如下方式组织的:
| 层的名称 | 描述 |
|---|---|
| conv1 | 卷积和线性整流激活函数 |
| pool1 | 最大池化 |
| norm1 | 局部响应归一化 |
| conv2 | 卷积和线性整流激活函数 |
| norm2 | 局部响应归一化 |
| pool2 | 最大池化 |
| local3 | 全连接层使用线性整流激活函数 |
| local4 | 全连接层使用线性整流激活函数 |
| softmax_linear | 线性转化产生逻辑回归 |
下面是TensorBoard生成的预测操作计算图
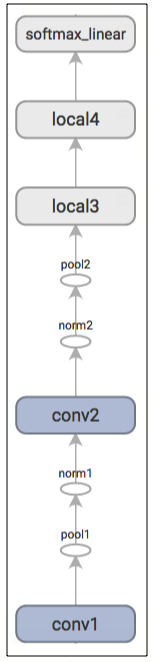
练习:
inference输出使用了非归一化的逻辑回归。尝试修改神经网络架构使用tf.nn.softmax返回归一化的预测。
函数inputs()和inference()提供了所有执行模型评估的所有要素。现在我们将焦点转移到构建训练一个模型操作上来。
练习:模型架构中的
inference()与在cuda-convent中描述的CIFAR-10有些不同。特别是Alex原来的模型中最高一层是局部连接而不是全连接。尝试修改架构在最高一层使用局部连接的架构。
模型训练
训练一个神经网络常用的N-Way分类方法是多类别逻辑回归,就是softmax识别。Softmax识别对神经网络的输出应用了一个softmax非线性函数并计算归一性预测和标签索引之间的交叉熵。对于正则化,我们也对所有已经学习的变量损失使用了常用的权重衰减。模型的目标函数是交叉熵损失和所有这些权重衰减项的合计值,使用loss()函数返回。
我们使用tf.summary.scalar在TensorBoard中进行可视化。
使用标准的梯度递减算法并使用随时间指数衰减的学习率来训练模型(其他方法参看训练页面)。
tain()函数增加的操作需要通过计算梯度并更新学习变量(详细信息参看tf.train.GradintDescentOptimizer)来达到最小的目标值。这个函数会返回一个操作来执行所有的训练计算并按每个批次的图片更新模型。
运行和训练模型
我们完成了模型的构建,现在运行脚本cifar10_train.py来运行训练操作。
python cifar10_train.py
注意:第一次运行CIFAR-10教程的脚本都会先自动下载数据集。数据集大概会有160MB,所以在第一次运行的时候可以喝杯咖啡了。
你应该看到如下的输出:
Filling queue with 20000 CIFAR images before starting to train. This will take a few minutes.
2015-11-04 11:45:45.927302: step 0, loss = 4.68 (2.0 examples/sec; 64.221 sec/batch)
2015-11-04 11:45:49.133065: step 10, loss = 4.66 (533.8 examples/sec; 0.240 sec/batch)
2015-11-04 11:45:51.397710: step 20, loss = 4.64 (597.4 examples/sec; 0.214 sec/batch)
2015-11-04 11:45:54.446850: step 30, loss = 4.62 (391.0 examples/sec; 0.327 sec/batch)
2015-11-04 11:45:57.152676: step 40, loss = 4.61 (430.2 examples/sec; 0.298 sec/batch)
2015-11-04 11:46:00.437717: step 50, loss = 4.59 (406.4 examples/sec; 0.315 sec/batch)
...
脚本报告了每10步总的损失值以及最后一个批次的处理时间。几个说明:
- 第一个批次的数据可能极其慢(比如几分钟),这是因为预处理线程要将20,000个CIFAR图片放到移动队列中。
- 报告的损失值是最新批次的平均值。记住这个值是交叉熵和所有权重衰减项的合计。
- 看一眼批次的处理速度。上面显示的这个数值是在Tesla K40c上获得的。如果你使用的是CPU速度会慢一些。
练习:在体验的过程中你会发现训练的第一个步骤要花很长的时间,这很令人沮丧。但是可以通过降低图片初始化填入队列的数量来进行改善。在
cifar10_input.py中搜索min_fraction_of_examples_in_queue。
cifar10_train.py会间断的保存所有模型参数到checkpoint文件中,但是它不会评估模型。checkpoint文件会被cifar10_eval.py脚本使用来衡量预测的性能(参看下面的评估模型部分)。
如果你按照前面的步骤已经开始训练一个CIFAR-10的模型。祝贺你!
终端的文本输出只是给出了cifar10_train.py模型训练很少的信息。需要更深入的了解模型训练的过程:
- 损失值是真的在下降还仅仅是噪声?
- 模型提供的图片合适吗?
- 梯度、激活函数和权重合理吗?
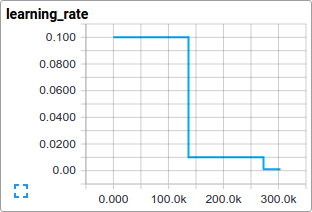
- 现在的学习率是多少?
TensorBoard提供这些功能,cifar10_train.py通过tf.summary.FileWriter的间隔导出的数据通过可视化的形式展现出来。
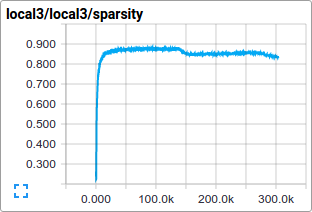
比如,我们可以查看参与训练过程的local3特征,它的激活函数分布和稀疏程度。
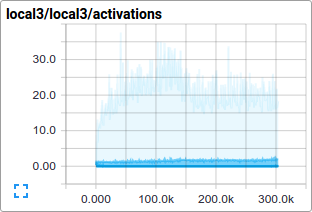
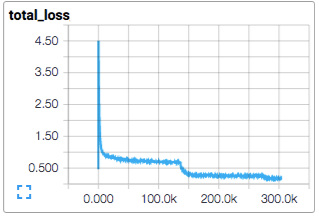
单独的损失函数以及合计损失值按时间序列展现特别有趣。但是损失值经常会有很多的噪声,这主要是因为在训练过程中批次过小。在实践中我们发现在原始数据上额外显示移动平均的值将非常有用。参看脚本是如何使用tf.train.ExponentialMovingAverage来达到这一目的的。
评估模型
让我们看一下在一个保留的数据集上训练好的模型表现如何。模型通过cifar10_eval.py进行评估。它使用inference()函数来构建模型,使用所有CIFAR-10评估集中10,000个图片。它会计算1值的准确性:最可能的预测能够匹配图片真标签的机率。
为了查看模型在训练过程中是如何提升的,评估脚本会间断的运行查看最新的cifar10_train.py产生的checkpoint文件。
python cifar10_eval.py
要小心不要同时在一个GPU上运行评估和训练,否则你可能会出现内存溢出的情况。如果可以考虑在不同的GPU上运行评估脚本,或者暂停训练在相同的GPU上进行评估。
你应该看到如下输出:
2015-11-06 08:30:44.391206: precision @ 1 = 0.860
...
这个脚本只会间断返回@1的准确率——这里返回的是86%的准确率。cifar10_eval.py也输出概要数据,也可以在TensorBoard中进行可视化输出。这些概要信息提供了额外的深入了解模型评估的过程。
训练脚本会计算所有已经学习变量的移动平均版本。而评估脚本会使用这个移动平均的版本来替换掉所有模型参数。这种操作会在评估的时候提升模型的效率。
练习:应用平均的参数按照测量
@1精度的标准可以提升预测准确率大概3%左右。编辑cifar10_eval.py在模型中不应用平均参数,验证一下预测性能的下降。
使用多个GPU卡训练模型
现在的计算科学工作站可能会有多个GPU。TensorFlow可以利用这种环境让训练在多个网卡上并行执行。
并行训练模型,分布的模式需要训练进程之间的协调。使用一个术语为模型副本的功能可以复制一部分模型训练的数据。
单纯使用异步更新模型参数会对训练的性能有一定影响,因为一个单独的模型副本可能是基于已经过期的模型参数。相反如果使用一个全同步的更新可能导致最慢的模型副本成为瓶颈。
有多个GPU卡工作站的每个GPU会有相似的速度并拥有足够的内存来运行整个CIFAR-10模型。因此我们将训练系统设计为以下模式:
- 在每个GPU上放置一个单独的模型副本。
- 在等待所有GPU完成批次数据处理后再同步更新模型参数。
模型的演示图如下:
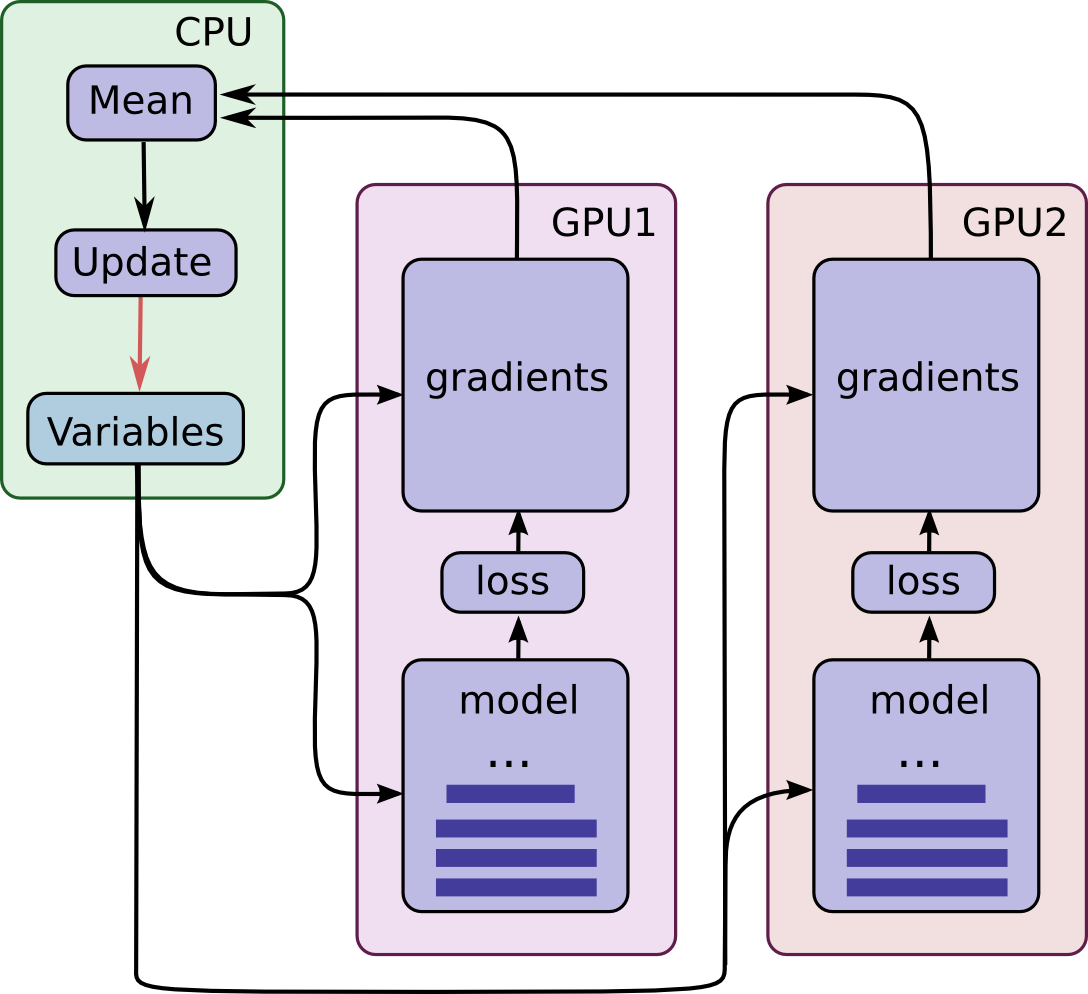
注意每个GPU为独立的数据批次计算预测和梯度。这样的设置有效的阻止了将大批量的数据跨GPU处理。
这样的设置需要所有的GPU都要共享模型参数。我们非常清楚从GPU传入传出数据是非常慢的。所以我们觉得在CPU中存储和更新所有的模型参数(参看绿色的框)。当新的批次数据要处理时新的模型参数将传送到GPU中。
GPU在同步执行。所有的梯度都在GPU中累加和平均(参看绿色框)。模型参数在所有模型副本中使用梯度平均值更新。
在设备上存放变量和操作
指定变量和操作到特定设备上需要一些抽象。
第一个抽象是我们需要一个函数来计算一个单独模型副本的预测和梯度。在代码中我们使用一个术语“tower”来表示。必须为tower设置两个属性:
- 在一个tower中所有操作要有一个唯一的名称。
tf.name_scope使用作用域前缀就能提供一个唯一的名称。例如所有第一个tower的操作都会使用前缀tower_0/conv1/Conv2D。 - 在一个tower内的操作要指定特定的运行硬件设备。
tf.device来进行指定。比如所有第一个tower内的操作都要使用device('/device:GPU:0')就是指定这个作用域内所有操作都要在第一个GPU上运行。
所有变量都固定在CPU上并使用tf.get_variable来访问,这样就可以在多GPU环境下共享变量。
在多GPU卡上运行和训练模型
如果你在自己的机器上安装了几个GPU,可以使用cifar10_multi_gpu_train.py脚本来让模型训练的更快。这个版本的训练脚本在多个GPU卡上并行训练。
python cifar10_multi_gpu_train.py --num_gpus=2
注意默认GPU数量是1。另外如果你只有一个GPU卡即使你指定了多个所有的计算也将在这一个卡上执行。
练习:默认
cifar10_train.py使用批的数量是128。可以在运行2个GPU环境下将批的数量指定为64来比较一下训练的速度。
下一步
恭喜!完成了CIFAR-10教程。
如果你现在对开发和训练你自己的图片分类系统感兴趣,我们建议你fork这个教程来完成自己图片分类问题。
练习:下载The Street View House Numbers(SVHN)数据集。Fork这个CIFAR-10教程并将数据替换成SVHN的数据。试着采用神经网络架构来改善预测的性能。